
True or false: if we want to achieve any degree of semantic interoperability in our clinical systems we need to standardise the clinical content, keeping it open and independent of any single implementation or messaging formalism?
Oil & water: research & standards
The world of clinical modelling is exciting, relatively new and most definitely evolving. I have been modelling archetypes for over 8 years, yet each archetype presents a new challenge and often the need to apply my previous experience and clinical knowledge in order to tease out the best way to represent the clinical data. I am still learning from each archetype. And we are still definitely in the very early phases of understanding the requirements for appropriate governance and quality assurance. If I had been able to discern and document the 'recipe', then I would be the author of a best-selling 'archetype cookbook' by now. Unfortunately it is just not that easy. This is not a mature area of knowledge. I think clinical knowledge modellers are predominantly still researchers.
In around 2009 a new work item around Detailed Clinical Models was proposed within ISO. I was nominated as an expert. I tried to contribute. Originally it was targeting publication as an International Standard but this was reduced to an International Specification in mid-development, following ballot feedback from national member bodies. This work has had a somewhat tortuous gestation, but only last week the DCM specification has finally been approved for publication - likely to be available in early 2014. Unfortunately I don't think that it represents a common, much less consensus, view that represents the broad clinical modelling environment. I am neither pleased nor proud of the result.
From my point of view, development of an International Specification (much less the original International Standard) has been a very large step too far, way too fast. It will not be reviewed or revised for a number of years and so, on publication next year, the content will be locked down for a relatively long period of time, whilst the knowledge domain continues to grown and evolve.
Don't misunderstand me - I'm not knocking the standards development process. Where there are well established processes and a chance of consensus amongst parties being achieved we have a great starting point for a standard, and the potential for ongoing engagement and refinement into the future. But...
A standards organisation is NOT the place to conduct research. It is like oil and water - they should be clearly separated. A standards development organisation is a place to consolidate and formalise well established knowledge and/or processes.
Personally, I think it would have been much more valuable first step to investigate and publish a simple ISO Technical Report on the current clinical modelling environment. Who is modelling? What is their approach? What can we learn from each approach that can be shared with others?
Way back in 2011 I started to pull together a list of those we knew to be working in this area, then shared it via Google Docs. I see that others have continued to contribute to this public document. I'm not proposing it as a comparable output, but I would love to see this further developed so the clinical modelling community might enhance and facilitate collaboration and discussion, publish research findings, and propose (and test) approaches for best practice.
The time for formal specifications and standards in the clinical knowledge domain will come. But that time will be when the modelling community have established a mature domain, and have enough experience to determine what 'best practice' means in our clinical knowledge environment.
Watch out for the publication of prEN/ISO/DTS 13972-2, Health informatics - Detailed clinical models, characteristics and processes. It will be interesting to observe how it is taken up and used by the modelling community. Perhaps I will be proven wrong.
With thanks to Thomas Beale (@wolands_cat) for the original insight into why I found the 13972 process so frustrating - that we are indeed still conducting research!
Clinical Knowledge Repository requirements
I've been hearing quite a lot of discussion recently about Clinical Knowledge Repositories and governance. Everyone has different ideas - ranging from sharing models via a simple subversion folder through to a purpose-built application managing governance of combinations of versioned knowledge assets (information models, terminology reference sets, derived artefacts, supporting documentation etc) in various states of publication. It depends what you want to achieve, I guess. In openEHR it became clear very quickly that we need the latter in order to provide a central resource with governance of cohesive release sets of assets and packages suitable for organisations and vendors to implement.
In our experience it is relatively simple to develop a repository with asset provenance and user management. What is somewhat harder is when you add in processes of collaboration and validation for these knowledge assets - this requires development of review and editorial processes and, ideally, display transparency and accountability on behalf of those managing the knowledge artefacts.
The most difficult scenario reflects meeting the requirements for practical implementation, where governance of configurable groups of various assets is required. In openEHR we have identified the need for cohesive release sets of archetypes, templates and terminology reference sets. This can be very complicated when each of the artefacts are in various states of publication and multiple versions are in use in 'on the ground' implementations. Add to this the need for parallel iso-semantic and/or derived models, supporting documents, and derived outputs in various stages of publication and you can see how quickly chaos can take over.
So, what does the Clinical Knowledge Manager do?
- CKM is an online application based on a digital asset management system to ensure that the models are easily accessed and managed within a strong governance framework.
- Focus:
- Accessible resource - creation of a searchable library or repository of clinical knowledge assets - in practice, a ‘one stop shop’ for EHR clinical content
- Collaboration Portal - for community involvement, and to ensure clinical models that are ‘fit for clinical use’
- Maintenance and governance of all clinical knowledge and related resources
- Processes to ensure:
- Asset management
- uploading, display, and distribution/downloading of all assets
- collaborative review of primary* assets to validate appropriateness for clinical use
- content
- translation
- terminology binding
- publication life cycle and versioning of primary assets
- primary asset provenance, differential and change log
- automatic generation of secondary**/derived assets or, alternatively, upload and versioning when auto generation is not possible
- upload of associated***/related assets
- development of versioned release sets of primary assets for distribution
- identify related assets
- quality assessment of primary assets
- primary asset comparison/differentials including compatibility with existing data
- threaded discussion forum
- flexible search functionality
- coordinate Editorial activity
- share notification of assets to others eg via email, twitter etc
- User management
- Technical management
- Reporting
- Assets
- Users
- Editorial activity support
- Asset management
In current openEHR CKM the assets, as classified above, are:
- *Primary assets:
- Archetypes
- Templates
- Terminology Reference Set
- **Secondary assets:
- Mindmaps
- XML transforms
- plus ability to add transforms to many other formalisms, including CDA
- ***Associated assets:
- Design documents
- References
- Implementation guides
- Sample data
- Operational templates
- plus ability to add others as identified
While CKM is currently openEHR-focused - management of the openEHR artefacts was the original reason for it's development - with some work the same repository management, collaboration/validation and governance principles and processes, identified above, could be applied for any knowledge asset, including all flavors of detailed clinical models and other clinical knowledge assets being developed by CIMI, or HL7 etc. Yes, CKM is a currently a proprietary product, but only because it was the only way to progress the work at the time - business models can always potentially be changed :)
It will be interesting to see how thinking progresses in the CIMI group, and others who are going down this path - such as the HL7 templates registry and the OHT proposed Heart project.
We can keep re-inventing the wheel, take the 'not invented here' point of view or we can explore models to collaborate and enhance work already done.
Quality indicators & the wisdom of crowds
Archetype quality I
Up until recently clinical content models, such as archetypes, have been regarded as a novelty; watched from the sidelines with interest from many but not regarded as mainstream. However now that they are increasingly being adopted by jurisdictions and used in real systems, modellers need to change their approach to include processes, methodologies and quality criteria that ensure that the models are robust, credible and fit for purpose. There has been some work done identifying quality criteria for clinical models but there is no doubt that establishing quality criteria for clinical content models is still very much in its infancy:
- Kalra D, Tapuria A, Freriks G, Mennerat F, Devlies J (2008). Management and maintenance policies for EHR interoperability resources [36 pages] (Q-REC Project IST 027370 3.3 ). The European Commission: Brussels. (Last accessed May 28, 2011)
- There has been some slowly progressing work in ISO TC 215 - ISO 13972 Health Informatics: Detailed Clinical Models. Recently it has been split into two separate components, not yet publicly available:
- Part 1. Quality processes regarding detailed clinical model development, governance, publishing and maintenance; and
- Part II - Quality attributes of detailed clinical models
Most of the work on quality of clinical models has been based largely on theory, with few groups having practical experience in developing and managing collections of clinical models, other than in local implementations.
In 2007, Ocean Informatics participated in a significant pilot project. The recommendations were published in the NHS CFH Pilot Study 2007 Summary Report. My own analysis, conducted in December 2007, revealed that there were 691 archetypes within the NHS repository. Of these, 570 were archetypes for unique clinical concepts, with the remainder reflecting multiple versions of the same concept. In fact, for 90 unique concepts there were 207 archetypes that needed rationalisation – most of these had only two versions however one archetype was represented in five versions! We needed better processes!
Towards the end of 2007 a small team within Ocean commenced building an online tool, the Clinical Knowledge Manager to:
- function as a clinical knowledge repository for openEHR archetypes and templates and, later, terminology subsets;
- manage the life-cycle of registered artefacts, especially the archetype content – from draft, through team review to published, deprecated and rejected. Also terminology binding and language translations;
- governance of the artefacts.
In July 2008 we started uploading archetypes to the openEHR CKM, including many of the best from the NHS pilot project. Over the following months we added archetypes and templates; recruited users; and started archetype reviews. All activity was voluntary – both from reviewers and editors. Progress has thus been slower than we would have liked and somewhat episodic but provided early evidence that a transparent, crowd sourced verification of the archetypes was achievable.
In early 2010, Sweden's Clinical Knowledge Manager had its first archetypes uploaded.
In November 2010, a NEHTA instance of the CKM was launched, supporting Australia's development of Detailed Clinical Models for the national eHealth priorities. This is where most collaborative activity is occurring internationally at present.
In this context, I have pondered the issues around clinical knowledge governance now for a number of years, and gradually our team has developed considerable insight into clinical knowledge governance – the requirements, solutions and thorny issues. To be perfectly honest, the more we delve into knowledge governance, the more complicated we realise it to be – the challenge and the journey continues; a lot is yet to be solved :)
It is relatively easy to identify the high level processes in the development of clinical knowledge artifacts, each of which requires identification of quality criteria and measurable indicators to ensure that the final artifacts are fit for purpose and safe to use in our EHR systems. The process is similar for both archetypes and templates; plus the Requirements gathering and Analysis components are applicable to any single overarching project as well.
For archetypes:
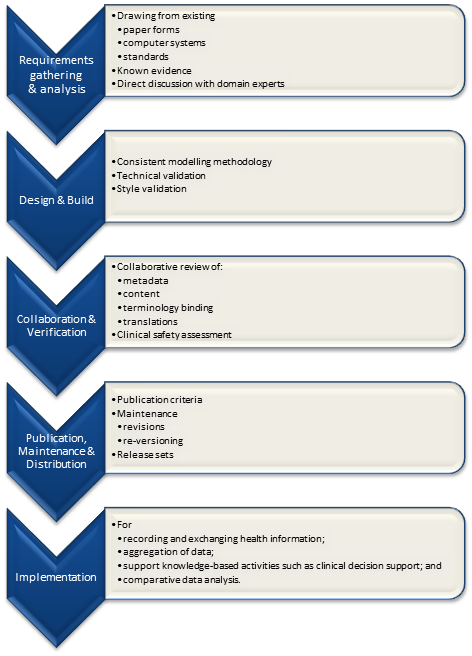
The harder task is that for each of these steps, there are multiple quality criteria that need to be determined, and for each criterion it will be necessary to be able to assess and/or measure them through identifiable quality indicators.
Ideally a quality indicator is a measurement or fact about the clinical model. In some situations it will be necessary to include additional assessments manually performed by qualified experts.
If an indicator can be automatically derived from the Clinical Knowledge Manager (CKM), it ensures that up-to-date assessments of the models are instantly available as the models evolve (such as this Blood Pressure archetype example), and more importantly, without reliance on manual human intervention. However while assessments that do need to be assessed by an expert human – for example, compliance to existing specifications or standards – add valuable depth and richness to the overall quality assessment, they also add a vulnerability due to the need for skilled human resources to not only conduct the assessment, but to apply consistent methodologies during the assessment; these will be much more difficult to sustain.
Assessment of whether the indicators actually satisfy the quality criteria should also ideally be as objective as possible, however our reality is that it will probably more often be subjective and vary depending on the nature of the archetype concept itself. The process cannot be automated, nor can there be a single set of indicators or criteria that will determine the quality of every archetype. We need to ensure appropriate oversight to archetype development, ensuring that a quality process has actually been followed and utilise quality indicators to determine if the quality criteria have been met - on an archetype by archetype basis.
Engaging Clinicians in Clinical Content (in Sarajevo)
Just browsing and found the link to our presentation for a paper the CKM team gave at the Medical Informatics Europe conference in Bosnia, 2009. Thought I'd share it here, in memory of an amazing conference and location:
MIE09: Engaging Clinicians in Clinical Content [PDF]
Our presentation:
[slideshare id=1958920&doc=engagingcliniciansinclinicalcontent-090906091020-phpapp02]
And the reference to Herding Cats is explained (a little) in the embedded video - actually an advertisement for EDS:
[youtube http://www.youtube.com/watch?v=Pk7yqlTMvp8&w=425&h=349]
I arrived after a 37 hour flight - Melbourne - London - Vienna - Sarajevo to join my Ocean CKM team - Ian McNicoll and Sebastian Garde. We presented our paper and also ran an openEHR workshop.
The conference was held at the Holiday Inn in Sarajevo - the hotel in which all the international journalists were holed up during the war, on 'Sniper Alley'.
Despite it being 14 years after the war had ended, raw emotions were palpable many times during the conference. That a pan-European conference was being held in his beloved Sarajevo under his auspice was a very overwhelming event for the Professor of Informatics and he was often seen in tears!
From my hotel room window in the centre of the city I could see 6 cemeteries.
Walking through the inner city we came across many cemeteries, thousands of marble gravestones with the majority representing the young men aged between 18 & 26.
Bullet holes were still very obvious on the walls of buildings.
Yet the city was vibrant, alive and welcoming.
I won't ever forget this visit.
Some photos of the experience:
{kind=link}












Is an incremental approach to EHRs enough?
Attending the International Council meetings on the first day of the recent Sydney HL7 meeting, the resounding theme was that of many countries focussed on messages, documents and terminology as the solution for our health IT future; our EHRs; health interoperability. 19 countries presented and 18 repeated this theme. The nineteenth HL7 affiliate, Netherlands, stood out in splendid isolation by declaring an additional focus on the development of clinical content.
Incremental EHRs?
This common message/document/terminology approach to EHRs is largely for historical reasons - safe, solid and incremental innovation; building on what has been proven successful before. It is not unique to health IT. It is not unique to HL7 either - it was just very obvious on the day.
In fact you can see this same phenomena in many places in everyday life - the classic example being the manufacturing of disposable shavers. First a one blade razor, then two blades, then three... But how long can this go on for? Is seven blades a reasonable thing? Eight? Will infinitely more blades make a difference to the shaving outcome or experience? When will blade makes stop and rethink their approach to innovation?
Certainly messages, documents and terminology are approaches that have commenced as often relatively isolated islands of work, had some successes, progressed and are now gradually being drawn together to create opportunities for some interoperability of health information. And don't get me wrong, there are absolutely some successes occurring. However, three questions linger in my mind about this approach:
- Is it enough?
- Is it sustainable?
- Will it achieve interoperable systems?
We all hear the rhetoric that if we can interconnect financial systems, then we can do it for health. We've tried this incremental approach for over 30 years and made significant progress but we definitely haven't cracked it yet.
 Messages
Messages
Paul Roemer used this diagram (right) to illustrate his view of the messaging exchanges in his blog post. I think the image is powerful, imparting both the complexity and chaos that an n-to-n messaging dependency will likely entail. The HIE approach might help, but ultimately a national approach to messaging will result in multiple images like this trying to connect to each other.
This is further complicated by messages often taking up to a year to negotiate between the sender and receiver, or potentially longer to successfully negotiate the national or international standards processes, and even then the resulting 'standard' is often being subjected to individual tweaks and updates at implementation in real-world systems where the 'one-size fits all' message doesn't meet the end-user's requirements.
In Australia the 'standard' pathology HL7 v2.x message is anything but standard with each clinical system vendor having to support multiple slightly different versions of the 'standard'. The big question is whether this is sustainable into the future.
In the US, the clinical content payload for the Direct project is yet to be determined and defined - "The project focuses on the technical standards and services necessary to securely transport content from point A to point B, and does not specify the actual content exchanged." This rings alarm bells for me.
I've been told that at one relatively large hospital system in the US, they require 30 permanent staff just to maintain their messages...! Whoa!!!
Messages and message networks try to be a simple incremental solution to interoperability. But are they really that simple? Are they sustainable? Locally, yes. Regionally, yes probably. Nationally? Internationally???
<My head hurts>
Documents
CDA documents featured highly on the HL7 agenda, with the current emphasis on simple documents, and increasingly we will welcome the inclusion of structured clinical content detail. Currently the content is HL7 v3 templates, but how will that content be standardised and support semantic interoperability?
Werner Ceusters describes semantic interoperability as:
Two information systems are semantically interoperable if and only if each can carry out the tasks for which it was designed using data and information taken from the other as seamlessly as using its own data and information.
Without working towards standardising clinical content we run the risk of our EHRs being little more than a filing cabinet full of unstructured documents that are human readable but not computer processable.
Terminology
We all need terminology, no matter which approach. That is an absolute given.
However the stand-out question that impacts all approaches is how to best 'harness' the terminology...
Interestingly the openEHR Board and the IHTSDO Management Board (SNOMED CT) have been talking about joining forces. An announcement on the openEHR site, in December 2010, states:
"At its October meeting in Toronto, the General Assembly of the IHTSDO received and discussed a proposal, submitted by its Management Board, to support, develop and maintain the IP in openEHR, within a broader framework of IHTSDO governance for clinical content of the electronic health record.
The openEHR Foundation Board has now heard from the IHTSDO Management Board, saying that, whilst the objective of the proposal was considered by the GA to be within the scope of the organisation and that it represented a pressing issue for their governments, it was unable to reach consensus that going forward with openEHR in this way is the right choice, at this time."
This suggests that the IHTSDO Management Board identified significant value in combining the structure of openEHR archetypes with SNOMED, enough to propose a stronger relationship. It will be interesting to see if these discussions continue to progress.
My view - this would be a game-changer. A common approach to using archetypes and SNOMED together is a potentially very powerful semantic combination.
An orthogonal approach - knowledge-driven EHRs

By contrast, the orthogonal approach taken by ISO 13606 & openEHR starts with computable, standardised clinical data definitions at the core - representing the clinical content within an electronic health record. The data definitions, comprising archetypes plus terminology, are the key. Messages and documents are derived from these content specifications and will therefore be internally consistent with the EHR data from which they were generated and if received into an archetype-enabled system can be incorporated, as described by Werner's definition above, as though generated in the receiving system ie semantic interoperability - no data transformation required. The openEHR communities of clinicians, informaticians and engineers are collaborating to agree and standardise these archetypes as a common starting point.
Working from standard content definitions will potentially make the development of documents and messages orders of magnitude simpler. If archetypes have been agreed and published via the CKM collaborative process, then engineers will be able to utilise these as building blocks for the creation of messages and documents for specific use cases, and for a multitude of other technical outputs.
The way forward?
Returning to the multi-blade EHR idea...
When will we stop, regroup and assess the merit of continuing as we are? Who will draw a line in the sand?
Difficult to answer.
Maybe never, maybe no-one.
openEHR/ISO 13606 may not be the right or final answer, but it does provide an alternative and orthogonal approach that has merit and is worth consideration.
Hopefully some of outcomes/proposed discussions from the recent HL7 meeting in Sydney will also contribute to clarifying a way forward.
Perhaps, even yet, we will devise a truly innovative approach to solving the difficulties of developing EHRs.
Don’t re-invent the (clinical content) wheel...
 It was with great interest that I read about the the recommendation for a universal exchange language in the recent release of the US report to the President: REALIZING THE FULL POTENTIAL OF HEALTH INFORMATION TECHNOLOGY TO IMPROVE HEALTHCARE FOR AMERICANS: THE PATH FORWARD.
I had asked the Direct project about the existence of a national plan for standardising clinical content only recently... It appeared that here was a plan after all.
It was with great interest that I read about the the recommendation for a universal exchange language in the recent release of the US report to the President: REALIZING THE FULL POTENTIAL OF HEALTH INFORMATION TECHNOLOGY TO IMPROVE HEALTHCARE FOR AMERICANS: THE PATH FORWARD.
I had asked the Direct project about the existence of a national plan for standardising clinical content only recently... It appeared that here was a plan after all.
So, to the report. The approach and benefits proposed started well...
The best way to achieve a national health IT ecosystem is to ensure that all electronic health systems can exchange data in a universal exchange language. The systems themselves could be designed in any manner desired — they could accommodate legacy systems that prevail or new recordkeeping systems and formats. The only requirement would be that the systems be able to send and receive data in the universal exchange language. (p41)
I have previously blogged about a universal health record underpinned by an application independent library of clinical content definitions, so the intent and benefits are well aligned with my preferred approach.
But then alarm bells started to ring....
Because of its multiple advantages, we advocate a universal exchange mechanism for health IT that is based on tagged data elements in an extensible markup language. If there were another equally good solution, it should also be considered; we have collectively been unable to think of one. (p43)
Issue #1: Isn't it more appropriate for step one to identify the need for standardised clinical content as a policy, rather than specify the format up front? Isn't that really the domain of health informatics experts as part of a subsequent work plan? I feel like we've skipped a couple of steps in the decision-making process. And are they really advocating the creation of this metadata-tagged XML from a zero starting point?
Issue #2: The last 9 words of that paragraph, "...we have collectively been unable to think of one." I'm glad that they are still open to equally good solutions being considered as indeed there are many ways that individuals, groups and organisations are exploring how to standardise clinical content definitions as the basis for a universal exchange mechanism.
In ISO TC 215, the International Standards Organisations Technical Committee for Health Informatics, there is a new work item which has been evolving for at least 2 years, although yet to attain committee draft status, known as ISO 13972 - Quality criteria for detailed clinical models. This work item is targeting a new international standard for determining quality criteria about the development of detailed clinical models - all clinical models, pick your flavour! In the world of international standards it has been recognised for years that with the plethora of different approaches to developing clinical models for EHRs, there is a need for some criteria to support quality aspect in their development. This work is being led by modellers from the Netherlands, with experts participating from the Australian, Danish, German, Swedish, US and Canadian standards organisations. Creating clinical content is definitely not a new field of endeavour by the time it enters the international standards arena.
So, I am extremely surprised that this expert PCAST group have not been able to 'collectively think' of an existing alternative.
In my last blog - Clinical Knowledge Governance in a Web 2.0 world – I pointed to a number of approaches to standardised clinical content to support health information exchange.
1. In the US – including, but by no means limited to:
- the HL7 standards organisation - where my UK colleague, Charlie McKay, informs me that there are more than 20 different approaches to clinical content development. Keith Boone (@motorcycle_guy) has posted his response to the PCAST report from a HL7 point of view - The Language of HealthIT;
- Stan Huff's group at Intermountain Health in Utah have had extensive experience in defining standardised clinical content across all of Intermountain's systems – they are leading experts in this domain; and
- I understand Don Mon and his team from AHIMA have also been working in this area.
2. In Europe, and Australia:
- The Australian National eHealth Transition Authority (NEHTA) has just launched a national clinician-led CKM approach to grassroots clinical content standardisation creating NEHTA's Detailed Clinical Models (DCMs).
- The Swedish national eHealth program has been actively working to integrate openEHR archetypes with its' VTIM architecture.
In addition, a few more points...
Firstly, the focus of the PCAST report is still only on data exchange, not on ensuring a sound foundation of a person-centric electronic health record. I'll say it again... get the data right and then the data will be able to be re-used, to multitask, be liquid, flowing to where it needs to be. It will become the solid foundation on which to build lifelong health records, simpler health information exchange, data integration & aggregation, research, reporting and knowledge-based activities. By focusing on exchange alone, then... you'll hopefully be able to exchange well and the rest will be considerably more uncertain.
Secondly, the proposed variant of XML is described as a 'straightforward' and 'superior' solution (p44), and the assumption that it will be scalable, protected by encryption, and that data element access services will be enough to support the health information exchange required. By contrast HL7, ISO/CEN 13606 and openEHR have taken decades to develop and refine underlying reference models to ensure that they have an unambiguous, consistent, secure way to represent personal health information – so you know who created the data, who is the subject of care, what the data means, what are the access rules applicable etc. In the openEHR environment, the specification authors developed Archetype Definition Language (ADL) for the purpose - and now part of the ISO 13606 standard - because the alternatives such as standard XML were not robust enough to represent health information. A 'straightforward' XML approach has a strong possibility of failure without a RM underpinning it.
And finally, there is the area of clinical knowledge governance itself. Health is dynamic, complex and diverse. The work required to represent healthcare as computable clinical content definitions or specifications is huge – don't underestimate the sheer volume of work that will be required. It is not realistic to expect a 'rapid mapping' of existing proprietary data structures into tagged data elements. Who will decide the clinical content in the models? If there are over 7000 clinical vendors in the US, which will be 'the source' or sources? Which are 'correct' or 'authoritative'? What methodology will be used to create the models? What level of granularity for each clinical element? How will they be aggregated together to represent clinical documents or events, and constrained to be useful for the clinical purpose? I have a million more questions...
Once the information models are defined, there will be a need for them to be validated before they can become the basis for a standardised or national clinical content library – suitable for consumers, clinicians, organisations, vendors, researchers and jurisdictions. A requirement will be recognised for life-cycle management and publication of these models, roadmaps for legacy data to migrate towards, and harmonise with, the new national health information 'source of truth', plus ongoing maintenance and governance.
Eric Browne stated in his recent blog, Recasting e-Health in the USA:
The work in Sweden, the UK, Singapore and even Australia, based on openEHR or ISO 13606 archetypes (i.e. implementable renditions of Detailed Clinical Models) is far more advanced and promising than that offered by the PCAST approach.
openEHR, which is my interest, has an approach to defining, agreeing and governing clinical content models for electronic health records, known as archetypes. It has taken more than 18 years to develop the openEHR technical specifications, and the last 10 years to achieve its' current approach and position in terms of clinical modelling. It is gaining traction, albeit with a modest volunteer community, especially now that it has a collaborative portal, known as the Clinical Knowledge Manager, to support sharing or models, reviews of clinical content, translation and terminology binding, and model governance.
Standardising health information definitions for health records or exchange is not a trivial task. Learn from what has already been achieved – all shapes, flavours and doctrines. Whatever you do, don't reinvent the wheel and create yet another universal language!
Clinical Knowledge Governance in a Web2.0 world
 Establishing and maintaining the quality of clinical knowledge is clearly the domain of the expert clinicians themselves. This is a broadly accepted principle for management and governance of the traditional clinical knowledge artefacts. However this assumption needs re-evaluation when we need to establish quality, safety and ‘fitness for purpose’ of computable clinical knowledge artefacts that populate Electronic Health Record (EHR) systems.
Clinical knowledge has traditionally been created and shared through formal publication and peer-review processes that have been adjudicated by committees of clinical experts. Those expert committees have been appointed through a credentialing process and have had jurisdiction and oversight over the entire publishable content – ‘the buck stops here’. Before the rise of the internet, face-to-face meetings have been where most of the committee work has been done, and the process has most often been slow and expensive but delivered good quality publications. The opportunity cost to each participating clinician has been high with recurring interruptions to their clinical activities. Revision of those publications at a later date repeats this process, taking considerable time, money and resources.
Establishing and maintaining the quality of clinical knowledge is clearly the domain of the expert clinicians themselves. This is a broadly accepted principle for management and governance of the traditional clinical knowledge artefacts. However this assumption needs re-evaluation when we need to establish quality, safety and ‘fitness for purpose’ of computable clinical knowledge artefacts that populate Electronic Health Record (EHR) systems.
Clinical knowledge has traditionally been created and shared through formal publication and peer-review processes that have been adjudicated by committees of clinical experts. Those expert committees have been appointed through a credentialing process and have had jurisdiction and oversight over the entire publishable content – ‘the buck stops here’. Before the rise of the internet, face-to-face meetings have been where most of the committee work has been done, and the process has most often been slow and expensive but delivered good quality publications. The opportunity cost to each participating clinician has been high with recurring interruptions to their clinical activities. Revision of those publications at a later date repeats this process, taking considerable time, money and resources.
Certainly in recent times, there have been more electronic tools to support these processes – email, teleconferences and videoconferences have improved the logistics of the process, but essentially the process remains unchanged.
Given the increasing traction of electronic health records, there is a parallel movement to develop and share computable clinical content definitions that can be created, published and implemented by: multiple clinical disciplines; generalists and specialists; primary, secondary and tertiary care organisations; population health planning; clinical researchers; and knowledge-enabled systems such as clinical decision support applications. They need to be language independent and translatable, in order to transport health information across national boundaries.
These kind of computable clinical models need the input from many experts, clinicians and others, to ensure that they are not only clinically appropriate but support safe data usage in our EHRs. These models are increasingly being created with ambitious goals – to create once and then re-use many times. In this case, the scope of the models needs to include requirements of the full breadth of clinical professions and specialties. Clinicians remain key to their development and publication, but they also require input from:
- Other domain experts – non-clinicians who will want or need to use these same models for non-clinical purposes such as secondary data use;
- Informaticians – who understand how these models will be the basis for recording health information, exchange between systems, reporting, data aggregation and how knowledge-based activities.
- Terminologists – to ensure that the models will integrate with appropriate terminology value sets;
- Technicians – who will advise on the technical impacts of these models in systems; and
- Translators – who will ensure that the clinical information is faithfully transformed from one language to another.
Examples of these computable clinical content models are many and varied. There are open source and proprietary models of many different flavours and philosophies – archetypes, templates, detailed clinical models etc. In recent years there are increasing attempts to broaden the input to the creation of these models and even to start to standardise them – regionally, nationally and even internationally. In this new paradigm, the traditional approaches to clinical content development, management and governance are no longer sufficient.
When the full breadth, depth, and dynamic nature of clinical knowledge is considered, it is not feasible to be able to appoint an overarching committee or board who would be capable of providing final ‘sign off’ about the clinical ‘correctness’ for any one model. Each clinical knowledge model will require input from varying groups of expert clinicians, terminologists, informaticians and technicians, depending on the clinical knowledge artefact under review. We need to find innovative approaches to online and asynchronous collaboration of a wide range of individuals from diverse backgrounds, expertise and geographical location to ensure these models are suitable for use in clinical systems.
Traditional standards bodies, such as ISO, CEN or HL7 have well defined and fixed processes in place for managing the lifecycle of technical standards through a formal balloting process with registered member bodies. These are definitely not suitable for managing and governing an evolving and dynamic clinical content specification library.
There has been some early work on establishing abstract archetype quality criteria by QREC and more recently, ISO TC 215 Working Group 1 has established a new work item 13972, which is establishing “Quality criteria for detailed clinical models”. However, neither of these are able to establish the quality of archetype instances for real world use.
I believe that HL7 is working to establish a Template Repository. As I understand it, it will operate as an indexing service to templates that will be stored on distributed servers. Others may be able to provide more details.
Other work is no doubt occurring, of which I am not aware. And of course, each clinical system has to establish the clinical content that it will use in its own proprietary information model. In the US alone, with thousands of clinical software vendors, this means that we have thousands of different computable versions of essentially identical clinical content, but none of it interchangeable without mappings or transformation – what a huge waste of resources! We need to change this blinkered way of thinking.
The openEHR Clinical Knowledge Manager (CKM) is the only online clinical knowledge resource, to my knowledge, which is supporting collaboration by clinicians, other domain experts, informaticians, technicians and translators to achieve consensus about quality and safety in clinical content models – in this instance, openEHR archetypes. I am directly involved in the development of this tool, and am active as an Editor facilitating the review process of the archetypes – I have described it in previous blog posts.
While CKM is one of the early Web2.0 approaches to collaborating about clinical content models, I am sure there will be more over time. I have spoken to a number of Knowledge Management experts, and to my surprise no-one has yet been able to point me to similar tools, resources establishing quality within a Web2.0 environment. Are we really such pioneers? Surely there are similar approaches in other knowledge domains?
No matter. There is no doubt that we are only in the early stages of a transformation in clinical knowledge governance and we have a lot to learn about how to establish quality criteria in a Web2.0 environment. I’ll post some thoughts in my next post...
An orthogonal question...
 Just askin'. Just curious...
What single eHealth activity, process or solution now available could:
Just askin'. Just curious...
What single eHealth activity, process or solution now available could:
- Ensure that EHR data is safe and ‘fit for clinical purpose’;
- Support data integration, data aggregation & comparative analysis;
- Simplify and support messaging and data exchange;
- Enable co-ordinated knowledge-based activities; and
- Provide a clear transition path for existing EHR applications towards common data representations.
...now there's a list that covers a broad range of eHealth, including may of our current, collective headaches, doesn't it!
The main thrust of the question is one that doesn't get asked very often, as it is orthogonal to our more common application- and messaging-driven approaches. It focuses on the most important part of any eHealth activities, yet it remains largely ignored - the quality and re-use of health information. Liquid data. Shareable data.
My opinion is that we need a clinical knowledge repository of common and agreed data definitions - that much should be clear from my other posts.
What other alternatives do you think can provide a solution in this knowledge space? How will we fill these needs?
Archetypes: the ‘glide path’ to knowledge-enabled interoperability
 In a world where connectivity is the universal aspiration, our health information is largely still caught up in silos and, in the main, is not accessible to those who need it – patients, clinicians, researchers, epidemiologists and planners. Shared electronic health records (EHRs) are increasingly needed to support the improvement of health outcomes by providing a timely, comprehensive and coordinated foundation for provision of healthcare. For decades people have been attempting to share health information, but the incremental approach has not been wholly successful – progress has been made, but despite enormous investment and resources, the solution has been found to be more difficult than most anticipated; many well-funded attempts have been stunningly unsuccessful. Healthcare provision appears not to fit the model that has been so successful in other domains such as banking or financial services. Why has sharing health information been so difficult? After all, on the surface, data are, simply, data.
In a world where connectivity is the universal aspiration, our health information is largely still caught up in silos and, in the main, is not accessible to those who need it – patients, clinicians, researchers, epidemiologists and planners. Shared electronic health records (EHRs) are increasingly needed to support the improvement of health outcomes by providing a timely, comprehensive and coordinated foundation for provision of healthcare. For decades people have been attempting to share health information, but the incremental approach has not been wholly successful – progress has been made, but despite enormous investment and resources, the solution has been found to be more difficult than most anticipated; many well-funded attempts have been stunningly unsuccessful. Healthcare provision appears not to fit the model that has been so successful in other domains such as banking or financial services. Why has sharing health information been so difficult? After all, on the surface, data are, simply, data.
Why is the health information domain different?
Health information is the most multifaceted and largest knowledge domains to try to represent in a computer. The SNOMED CT terminology alone has over 450,000 terms expressing health-related concepts, and our collective knowledge about health is far broader, deeper and richer than that required to represent financial systems. The added bonus in health is that our information domain is dynamic - growing and changing as our understanding increases.
Recording, communicating and making sense of health information is something that clinicians do remarkably well in a localised, non-digital world. However the human cognitive processes and assumptions that underpin the traditional health records do not easily translate into the computerised environment. Consider the need for narrative versus structured data; the complexity of clinical statements; use of the same data in a variety of clinical contexts; the need for clinicians to make ‘normal’ or ‘nil significant’ statements, and also the oft underrated positive statements of absence; and the need for graphs, images or multimedia in a good health record. Grassroots clinicians have different personal preferences for creating their clinical records and to support their requirements for direct provision of clinical care and communication to colleagues. In parallel, jurisdictions have different expectations of the grassroots clinical data collection that will support reporting, data aggregation and secondary use of data.
Throw into this mix the complex and convoluted processes required to support healthcare provision; mobile patient populations; and the need for lifelong health records, and it starts to become easier to understand why eHealth has been more of a challenge that many first thought.
Information-driven EHRs
Traditional approaches to the development of EHRs have been software application-driven, hard-coding clinical knowledge into the proprietary data model for each software system and resulting in silos of health information locked away in proprietary databases. This is valuable data, and even more valuable if we can get access to it, exchange it and utilise it. Key stakeholders – patients, clinicians, researchers, planners and jurisdictions – are currently disempowered and are not easily able influence or express their data requirements. We have mistaken the software application for the electronic health record - a classic example of the ‘tail wagging the dog’.
If we focus on the electronic health record being the data, we turn the traditional paradigm upside down. Our EHRs become information-driven by putting the stakeholders at the centre to direct the information content and quality aspects of our EHR systems. It is only then that our systems will be able to reflect the real requirements of stakeholders, ensuring that health information collected data is ‘fit for use’ and will support personal health records, clinician health records and, with appropriate authorisation and permissions, the broadest range of secondary use.
Sharing health information requires common and coherent health information definitions or models – ensuring that health information can be expressed in a way that is meaningful to stakeholders AND that computers can process it. According to Walker et al , Level 4 interoperability, or ‘machine interpretable data’, comprises both structured messages and standardised content/coded data. In practice, it means that data can be transmitted and viewed by clinical systems without need for further interpretation or translation. This semantic, or knowledge-level, interoperability is absolutely required for truly shareable health records, data aggregation, knowledge-based activities such as clinical decision support, and to support comparative analysis of health data. Further, it is only when this health information model is agreed at a local, regional, national or international level, that true semantic interoperability can occur at each of these levels. The broader the level of clinical content model agreement, the broader the potential for semantic health information exchange.
The openEHR paradigm
openEHR is a purpose-built, open source, information-driven electronic health record architecture focused on ensuring that the grassroots health information is recorded clearly, coherently and unambiguously in EHRs, and supporting re-use in other contexts where appropriate. It adopts an orthogonal approach to EHRs - a dual-level modelling methodology with clear separation of the technical from the clinical domains, where software engineers focus on their application development and the clinical domain experts focus on the health information definitions. openEHR focuses on the data - using computable knowledge artefacts known as archetypes and templates to formally express health information.
openEHR archetypes are computable definitions created by the clinical domain experts for each single discrete clinical concept – a maximal (rather than minimum) data-set designed for all use-cases and all stakeholders. For example, one archetype can describe all data, methods and situations required to capture a blood sugar measurement from a glucometer at home, during a clinical consultation, or when having a glucose tolerance test or challenge at the laboratory. Other archetypes enable us to record the details about a diagnosis or to order a medication. Each archetype is built to a ‘design once, re-use over and over again’ principle and, most important, the archetype outputs are structured and fully computable representations of the health information. They can be linked to clinical terminologies such as SNOMED-CT, allowing clinicians to document the health information unambiguously to support direct patient care. The maximal data-set notion underpinning archetypes ensures that data conforming to an archetype can be re-used in all related use-cases – from direct provision of clinical care through to a range of secondary uses.
Templates are used in openEHR to aggregate all the archetypes that are required for a particular clinical scenario – for example a consultation or a report. These can also be shared, preventing more ‘wheel re-invention’. Individual content elements of each maximal archetype can be ‘disabled’ in the template so that the only data elements presented to the clinician are those that conform to national or local requirements and are relevant and appropriate for that use-case scenario. For example, a typical Discharge Summary may commonly comprise 10 common archetypes; templates allow the orthopaedic surgeon to express a slightly different ‘flavour’ of the Discharge Summary based on which elements of each archetype being either active or disabled, compared to that required by a Obstetrician who needs to share information about both mother and newborn. One ‘size’, or document, does not fit all. The archetypes, as building blocks, are the key to semantic interoperability; while templates allow flexible expression of the archetypes to fulfill use-case requirements.
How achievable is this? Only ten archetypes are needed to share core clinical information that could save a life in an emergency or provide the majority of content for a discharge summary or a referral. If each archetype takes an average of six review rounds to reach clinician consensus and each review round is open for 2 weeks, it is possible to obtain consensus within an average of three months per archetype – some complex or abstract ones may be longer; other simpler, more concrete archetypes will be shorter. Many archetypes are already well developed in the international arena and within national programs. As archetype reviews can be run in parallel, a willing community of clinicians could achieve consensus for core clinical EHR content within three to six months.
It is estimated that as few as fifty archetypes will comprise the core clinical content for a primary care EHR, and maybe only up to two thousand archetypes for a hospital EHR system including many clinical specialties. The initial core clinical content will be common to all clinical disciplines and can be re-used by other specialist colleges and interested groups. More specialised archetypes will gradually and progressively be added to enhance the core archetype pool over time.
The openEHR Clinical Knowledge Manager (CKM) is an online clinical knowledge management tool – www.openEHR.org/knowledge - which provides a repository for archetypes and other clinical knowledge artefacts, such as terminology subsets and document templates. Based on a data asset management platform it provides a clinical knowledge ecosystem supporting the publication lifecycle and governance of the archetypes. Within CKM, a community of grassroots clinicians and health informaticians collaborate in online reviews of each archetype until consensus is reached and the agreed archetype content is published. Clinicians and other domain experts need no technical knowledge to engage with archetypes - the technical aspects of archetypes are kept hidden ‘under the bonnet’ – but they use their expertise to ensure that the content definitions within each archetype is correct and appropriate. Each content review is conducted online at a time of convenience to the clinician and usually only takes five to ten minutes for each participant. Thus the clinical domain experts themselves drive the archetype content definitions, and CKM has become a peer-reviewed knowledge resource for all parties seeking shared, standardised and computable health information models.
At the time of writing CKM has acquired, largely by word of mouth, 565 registered users from 62 countries, including 181 people who have volunteered to review archetypes, and 73 who have volunteered to translate archetypes. The repository contains 273 archetypes, of which 15 have content that are in team review and 9 published. Two example templates have been uploaded, and we await final publication of the openEHR template specification before we expect to see template activity increase. Terminology subset functionality has been added only recently and our first terminology subsets uploaded. So, while CKM is still relatively new, its Web2.0 approach to artifact collaboration and publishing, combined with formal knowledge artifact governance positions CKM as a pioneering ‘one stop shop’ for clinical knowledge resources online.
Current CKM functionality includes:
- Display of artefacts including structured views, technical representations and mind maps to make it easy for clinicians and others to review;
- Uploading of new knowledge artefacts – archetypes, templates and terminology subsets – for review and publication;
- Archetype metadata supporting classification, ontological relationships and repository-wide searches;
- Digital asset management including provenance and artefact audit trail;
- Integration with openEHR tools supporting quality assessment & technical validation checks;
- Review and publication process for clinical content – draft, team review, published and reassess states
- Terminology binding and terminology subset reviews;
- Online archetype translation with review;
- Community engagement via threaded discussions, repository downloads, attached resources, watch lists, email notifications, user dashboards and release sets;,
- Editorial support via To Do lists, user and team administration, review management, artefact modification, classification management, broadcast emails etc;
- Subscriber auto-notification including Twitter and email
- Reports – Archetypes, Templates and Registered users
A governed repository of shared and agreed archetypes will provide a ‘glide path’ towards full semantic interoperability of health information; a clear forward path for standardisation of data definitions. These will bootstrap new application or program development, provide a ‘road map’ to support gradual transition of existing systems to common data representation and provide the means to integrate valuable silos of legacy data.
Benefits of a collaborative, data-driven approach
A collaborative and domain expert-led approach to our health information provides many benefits which include the following.
Benefits for stakeholders
- Active involvement of domain experts to ensure the safety and quality of health information.
- Development of a coherent set of health information definitions:
- Improved data quality – shared core clinical content plus specialised domain-specific content will be agreed and ratified by the domain expert community; health information created will need to conform to the agreed archetype specifications.
- Improved data ‘liquidity’ – specifications to support exchange, flow and re-use of health information - from direct patient care through to secondary use of data. Improved data longevity – shared non-proprietary health information definitions minimise need for data transformations or system migration and the inherent risk of data loss; will support the cumulative, lifelong health records and longitudinal data repositories;
- Improved data availability – easier integration of health information from disparate sources when based on common archetype definitions;
- Re-use, integrate and aggregate data for supporting quality processes such as clinical audit, reporting and research; and
- Break down the existing ‘silos’ of health information based on proprietary and varied definitions.
- Online collaboration maximises the potential for a breadth of grassroots stakeholder engagement in ensuring correctness of the health information definitions.
- Active participation by clinical domain experts to shape and influence their EHRs, ensuring that EHR content is ‘fit for clinical purpose’.
- Online participation in clinical content review will be of short duration and at times of convenience to the clinician, avoiding the significant time and opportunity cost of attendance at face-to-face meetings.
Benefits for patients
- Data created and stored in a shared, standardised and non-proprietary representation supports the potential for application-independent data records that can persist for the life of the patient.
- Improved data ‘liquidity’ – so that data can flow between healthcare providers and systems to where the patient needs it.
Benefits for national programs and other jurisdictions
- Development of a coherent national set of clinical content specifications to support the shared EHR programs, health information exchange and secondary use.
- Enables national governance of foundation clinical content while at the same time facilitates flexible expression of local domain requirements
- Efficient use of sparse clinical, informatics and stakeholder resources:
- Design & create an archetype once; re-use many times;
- Leveraging existing clinical specification work done internationally to improve local national pool of archetypes;
- Online collaboration maximise the potential for stakeholder engagement at the same time as minimising the requirement for expensive face-to-face meetings; and
- Review and publication of agreed clinical specification definitions within weeks to months;
- Review and standardisation of clinical documents containing agreed archetypes will be relatively short.
- • Clinical knowledge management ecosystem:
- Single national repository of clinical knowledge artefacts, including archetypes and terminology subsets.
- Focussed and coordinated knowledge management environment where all stakeholders can observe, participate and benefit; the opposite of the current fragmented, isolated and proprietary approach to defining health information content.
- Digital knowledge asset management:
- Manages authoring, reviewing, publication and update lifecycle of all knowledge assets;
- Provenance and asset audit trails;
- Ensures asset compliance to quality criteria;
- Ensures technical validation of assets; and
- Development of coherent release sets for implementers;
- Governance of knowledge assets.
- Distribution of knowledge assets via coherent release sets.
- Removes the need for per message or per document negotiation between application developers, organisations and jurisdictions each time information needs to be integrated or exchanged by use of the standardised content within more generic message wrappers or document structures.
- Transparency of editorial and publishing processes; accountability to the domain expert community itself.
- Precludes the need for ratification of clinical or reporting documents through a traditional standards process when they consist of subsets of the nationally agreed archetypes.
Benefits for application developers
- Download coherent sets of clinical content definitions from a published and agreed national repository – not re-inventing the wheel by defining each piece of health information over and over.
- Software development remains focused within the expert technical domain – user interface; workflow processes; security, data capture, storage, retrieval and querying; etc.
- Removes the need for per message or per document negotiation between vendors, organisations and jurisdictions each time information needs to be integrated or exchanged by use of the standardised content within more generic message wrappers or document structures.
Benefits for secondary users of data
- Existing data can be mapped to archetypes once only, and transformed into a validated and consistent format; new data can be captured and aggregated according to the same national archetype definitions.
- Data stored in a common representation can be more easily aggregated and integrated.
- Access to valuable legacy data that would otherwise be unavailable.
Agreed and shared representations of the health information, embracing existing stakeholder requirements and developed rapidly by an active online community, will kick-start and accelerate many currently fragmented eHealth activities. Sharing archetypes as the definition of our health information will not only provide a common basis for recording and exchanging health information but also simplify data aggregation of data, support knowledge-based activities and comparative data analysis. Perhaps even more compelling, we are making certain that our domain experts warrant that the data within our EHRs, and flowing between stakeholders, is safe and 'fit for purpose'.
The state of the CKM!
 The openEHR Clinical Knowledge Manager (CKM) is a unique resource for the specification of health information that will become part of people’s lifelong health record. The work raises questions. What more do we need to develop and manage high quality specifications for health information suitable for sharing between clinical applications? How do we manage the tension between harnessing the richness of contributions from the large and enthusiastic community of clinicians and health informaticians and ensuring that the specifications are comprehensive and internally consistent? This has been weighing on my mind over the past couple of years as our team have developed a Web 2.0 approach to openEHR clinical knowledge collaboration.
CKM is an international, online clinical knowledge repository providing digital asset management throughout the authoring, reviewing, publication and update lifecycle of these specifications. It has been designed to provide governance capabilities, and facilitates collaboration by registered participants. The full range of openEHR clinical knowledge resources - archetypes, templates and terminology subsets – are now managed in this environment.
The openEHR Clinical Knowledge Manager (CKM) is a unique resource for the specification of health information that will become part of people’s lifelong health record. The work raises questions. What more do we need to develop and manage high quality specifications for health information suitable for sharing between clinical applications? How do we manage the tension between harnessing the richness of contributions from the large and enthusiastic community of clinicians and health informaticians and ensuring that the specifications are comprehensive and internally consistent? This has been weighing on my mind over the past couple of years as our team have developed a Web 2.0 approach to openEHR clinical knowledge collaboration.
CKM is an international, online clinical knowledge repository providing digital asset management throughout the authoring, reviewing, publication and update lifecycle of these specifications. It has been designed to provide governance capabilities, and facilitates collaboration by registered participants. The full range of openEHR clinical knowledge resources - archetypes, templates and terminology subsets – are now managed in this environment.
Under the auspice of the openEHR Foundation, our goal is to offer a clinical knowledge management ecosystem in which: the knowledge artefacts are based on open specifications; the service and programming interfaces are openly specified; and the production data representations are also openly specified. Archetypes are freely available under a Creative Commons license.
 The focus of CKM to date has been to publish a coherent set of archetypes that can be use by national body or health application developers in projects that involve shared EHRs. These archetypes have developed in different projects, including work in partnership with the UK, Singapore, Australian and Swedish eHealth Programs and in collaboration with clinical application developers building working systems. The work has also been influenced by the openEHR international community’s proposal to develop a set of high quality archetypes to support a shared Emergency summary. These ‘top 10’ archetypes define core clinical content in many common clinical scenarios.
The focus of CKM to date has been to publish a coherent set of archetypes that can be use by national body or health application developers in projects that involve shared EHRs. These archetypes have developed in different projects, including work in partnership with the UK, Singapore, Australian and Swedish eHealth Programs and in collaboration with clinical application developers building working systems. The work has also been influenced by the openEHR international community’s proposal to develop a set of high quality archetypes to support a shared Emergency summary. These ‘top 10’ archetypes define core clinical content in many common clinical scenarios.
The intent for current CKM archetype design is to make it possible for them to be used across any and all clinical systems - ‘global’ archetypes. By design these archetypes:
- Are a maximal dataset to maximise inclusiveness and uptake;
- Are re-usable across universal use cases;
- Are an internally consistent set;
- Minimise model overlap;
- Are based on generic patterns (which are evolving and design pattern principles are becoming clearer);
- Support further specialisations to meet local or specific domain requirements; and
- Provide design guidance for archetype development for similar concepts.
The draft archetypes currently in CKM do not meet all these requirements but as they progress through the publication process are brought closer to this ideal. As requirements develop (and health care changes) the archetypes will be revised always seeking to maintain universal sharing of the very important health information held in a lifelong record.
 At the time of writing CKM has acquired, largely by word of mouth, 556 registered users from 62 countries, including 179 people who have volunteered to review archetypes, and 72 who have volunteered to translate archetypes. The repository contains 273 archetypes, of which 15 have content that are in team review and 9 published. Two example templates have been uploaded, and we await final publication of the template specification before we expect to see templating activity increase. Terminology subset functionality has been added only this week and our first SNOMED subsets uploaded. This enables CKM to become a ‘one stop shop’ for clinical knowledge resources online.
At the time of writing CKM has acquired, largely by word of mouth, 556 registered users from 62 countries, including 179 people who have volunteered to review archetypes, and 72 who have volunteered to translate archetypes. The repository contains 273 archetypes, of which 15 have content that are in team review and 9 published. Two example templates have been uploaded, and we await final publication of the template specification before we expect to see templating activity increase. Terminology subset functionality has been added only this week and our first SNOMED subsets uploaded. This enables CKM to become a ‘one stop shop’ for clinical knowledge resources online.
Current CKM functionality includes:
- Display of artefacts including structured views, technical representations and mind maps to make it easy for clinicians and others to review;
- Uploading of new knowledge artefacts – archetypes, templates and terminology subsets – for review and publication;
- Archetype metadata supporting classification, ontological relationships and repository-wide searches;
- Digital asset management including provenance and artefact audit trail;
- Integration with openEHR tools supporting quality assessment & technical validation checks;
- Review and publication process for clinical content – draft, team review, published and reassess states
- Terminology binding and terminology subset reviews;
- Online archetype translation with review;
- Community engagement via threaded discussions, repository downloads, attached resources, watch lists, email notifications, user dashboards and release sets;,
- Editorial support via do lists, user and team administration, review management, artefact modification, classification management, broadcast emails etc;
- Subscriber auto-notification including Twitter and email
- Reports – Archetypes, Templates and Registered users
Transparency is a key principle within CKM. Editors are accountable to the community at every step; all comments, review rounds, changes etc. within CKM can be seen by the users. This ensures that if a user flags an issue, it is managed publicly and the user community can comment on the resolution.
Editorial work and fine-tuning the archetypes towards publication takes time and with a small number of volunteer editors the work has been a little slower than anticipated. Interestingly the rate limiting step at present is availability of the editorial support, NOT an interested community willing to contribute their expertise – joining the community largely only by word of mouth, they are motivated and willing to contribute whenever requested!
Yet we are very pleased with our modest achievements to date:
- A reasonably robust tool built through real experience;
- Established processes for the transparent governance of the range of openEHR-related clinical knowledge artefacts; progressively fine-tuned as we identify and understand the issues involved; and
- A motivated community supporting us and keen to participate in a web 2.0 environment.
Perhaps most important is what has been learned about knowledge governance – a relatively new domain. We anticipated complexity and the more we advance the CKM tool, the more we discover! This is an exciting and challenging journey.
We are ready now to encourage and embrace greater participation - harnessing the collective intelligence of the CKM community - through development of an archetype ‘pool’ where users can share their work on archetypes, templates and terminology subsets - a stepping stone into the tightly governed 'global' archetype pool. Some of these community archetypes will be developed for other purposes than the ‘maximal data set, universal use case’ scenario and provide valuable intermediate steps to support existing protocols and work to be used in a shared health record. We want to enable these to be shared and reused while at the same time encouraging work towards more general and broadly shareable solutions – all will benefit if we can share and learn from each other.
We continue to look for ways to help developers and implementers get what they need from CKM and this is an ongoing work. One important development is the ability to federate instances of CKM with the international openEHR service which offers a way of keeping national/jurisdictional efforts aligned but independently managed. Release sets of coherent archetypes are also a high development priority.
There are a diverse set of requirements and a growing set of artefacts – no simple one size solution that fits all. We can’t simply declare that we need a ‘top down’ or ‘bottom up’ approach. Sometimes leadership will be key, sometimes democracy.We are aiming for a pragmatic mix, with accountability to the community through transparency of process being paramount.
To our thinking, generating formal and computable health information specifications conveniently and openly on the web by a motivated, international community of grassroots clinicians, informaticians and implementers is potentially world-changing. And perhaps even more exciting, we are enabling our domain experts, the clinicians themselves, to make sure that the data within our EHRs is safe and 'fit for purpose'.
We are on a journey to create a clinical knowledge ecosystem – and this is the state of the CKM!
Special thanks to Sam Heard for his editorial assistance.
And to the CKM team - Sam Heard (@samheardoi) in Australia, Ian McNicoll (@ianmcnicoll) in Scotland and Sebastian Garde (@gardes) in Germany.
Don't forget to follow @openEHRckm for notification of CKM activity and updates.